
お手元の CSV ファイルを手軽に加工しようと思った場合、EXCEL 等のアプリケーションに取り込んで利用するのが一般的かと思います。
まぁ、ほとんどの場合はそれで十分なのですが。
「65,536 行までしか扱えない古いバージョンを考慮しなくてはいけない環境なので、そもそも EXCEL に取り込む為のデータを CSV から必要な分だけ抽出したい」
ですとか、
「こっちとあっちの CSV を結合した結果を加工して出力したい」
ですとか、
「てゆうか、 直接 CSV に SQL で問い合わせたいんじゃー」
みたいな欲求が、この記事を開いたような方には稀に良くあるのだと思います。
そこで、今回は CSV に SQL で問い合わせる方法について、JOIN 等も考慮しつつ、なるべく色々なケースを見た上で、最後に簡単な比較をしてみようと思います。
また、GUI アプリケーションを使った方法も、少しですが載せておきますので、コンソールなんてかったるくて使ってらんねーぜ、という方はそちらをどうぞ。
読み込み中です。少々お待ち下さい
まずは、前提から
当記事では、利用者が多いであろう Windows 環境を踏まえて説明していきます。
今回のような記事では、実際は Unix ライクな環境の方がなにかと説明し易い場合が多いのですが、Linuxer や MACer は、まぁ、自分で適宜読み替えてなんとかできるでしょう、と。
また、サンプルとして、以下の CSV が「D:\temp\csv」に保存されているものとします。
product.csv
"PRODUCT_CODE","PRODUCT_NAME","PRICE"
1,"商品1",100
2,"商品2",200
3,"商品3",150
customer.csv
"CUSTOMER_ID","FIRST_NAME","LAST_NAME", "COUNTRY"
1,"1号","ぐーたら","US"
2,"2号","ぐーたら","JP"
journal.csv
"ORDER_NO","PRODUCT_CODE","PURCHASE_PRICE","CUSTOMER_ID","PURCHASE_DATE"
1,1,95,2,16-01-01
2,2,190,2,16-01-01
3,2,190,2,16-01-01
4,1,100,1,16-01-02
5,2,200,1,16-01-02
6,3,150,1,16-01-02
7,3,150,1,16-01-05
8,3,150,1,16-01-08
Apach Drill
そもそもですね、つい先日、ちょっとした事情でお手軽に CSV を加工したくなりまして。
なに使おっかなーと考えた時に、「いやぁ、イマなら Apache Drill を試してみるしかないっしょ」と思い付いたのが、この記事の発端なのです。
詳しいことは、本家のドキュメントに譲りますが、この Apache Drill、かなり大層な代物でして、端的に言うと分散処理を前提とした NoSQL 向けの SQL クエリエンジンということになるのですが(難しい日本語)、色々な種類のデータソースを組み合わせて取り扱うことができるという側面があるんですね。
ここでの趣旨に準じて例えるならば、CSV と JSON を JOIN できたりする訳です。
と聞いて、「いやいやいや」と思った方も多いでしょうが、そうなんですよ、CSV やら JSON やらをお手軽に加工する目的で導入するには、ちょっと重厚長大過ぎるんですよね、これ。
周辺情報を漁っていると、Hadoop やら Hive やら HBase やらの固有名詞がビュンビュンと飛び交うことからも察せられるように、どうせなら規模の大きい案件で真面目に使うべきというか――
「い、いや、ホント、そんなちゃんとしてなくていいんス、マジ、ちょっと軽く CSV に SQL 投げてみたかっただけなんで、自分、ホントすんませんッした!!」
みたいに腰が引ける感じというか。
Windows だと、64 bit 環境にしか対応してませんしね。
とはいえ、CSV に対してクエリを投げる程度のことは簡単にできますから、いちおう方法を見ていきましょう。
- まず、自分の環境に Java 7 以降がインストールされていない場合は、最新版をダウンロード&インストールしてください。
プログラミングは一切するつもりがない、という場合は JRE でも大丈夫だと思いますが、どうせなら JDK でいいんじゃないでしょうか。
OpenJDK でも、特に問題は無いかと思われますが、試していないのでなんとも言えません。また、必要に応じて環境変数「JAVA_HOME」に JDK をインストールしたフォルダを設定し、「PATH」の先頭に「%JAVA_HOME%\bin」を追加してください。
- 本家から Apache Drill のアーカイブをダウンロードして展開します。
(2016/01/20 現在は apache-drill-1.4.0.tar.gz)
インストール作業等は特に必要無く、単純に解凍するだけで大丈夫です。 - 「D:\temp\apache-drill-1.4.0」に展開したとして、コマンドプロンプトを開いて、以下のコマンドで bin に移動します。
cd D:\temp\apache-drill-1.4.0\bin - bin に移動したら、以下のコマンドを実行して Embedded Mode で起動します(Embedded Mode について、詳しくはこちら)
sqlline -u "jdbc:drill:zk=local" - そして、こんな感じで問い合わせを実行すると――
- はい。これで、デフォルトだと文字コードは UTF-8、改行コードは \n(LF)でないといけないことが分かりましたね。
- さて、せっかくの Drill ですから、試しに適当な JSON を作って CSV と結合してみましょう。
- Drill Shell を終了するには、「!quit」+エンターを入力します。
SELECT * FROM dfs.`D:\temp\csv\product.csv`;
(「dfs」は小文字で入力してください。また、「`」はシングルクォーテーションではなく、Shift+@ で入力するバッククォートです)
このような結果が出力されます
0: jdbc:drill:zk=local> SELECT * FROM dfs.`D:\temp\csv\product.csv`;
+------------------------------------------+
| columns |
+------------------------------------------+
| ["PRODUCT_CODE","PRODUCT_NAME","PRICE"] |
| ["1","???i?P","100\r"] |
| ["2","???i?Q","200\r"] |
| ["3","???i?R","150\r"] |
+------------------------------------------+
ということで、テキストファイルをそのように修正した上で、再度問い合わせてみましょう。
0: jdbc:drill:zk=local> SELECT * FROM dfs.`D:\temp\csv\product.csv`;
+------------------------------------------+
| columns |
+------------------------------------------+
| ["PRODUCT_CODE","PRODUCT_NAME","PRICE"] |
| ["1","商品1","100"] |
| ["2","商品2","200"] |
| ["3","商品3","150"] |
+------------------------------------------+
今度は大丈夫そうです。Windows も 10 から UTF-8 をデフォルトにすれば良かったのに。
文字コードの変換に関して、Windows 標準のメモ帳でも UTF-8 の保存はできますが、残念ながら改行コードが指定できません。
メモ帳以外の、多少高級なテキストエディタであればどれでも可能ですが、お手元に何も無い場合は、以下の 1 行を「CharConv.java」という名前で保存して、コンパイル&実行すると、第1引数で指定したファイルを UTF-8 に変換して出力できます。
CharConv.java
import java.io.*; public class CharConv { public static void main(String[] args) throws Exception { String l; String f = args.length > 1 ? args[1] : "Windows-31J"; String t = args.length > 2 ? args[2] : "UTF-8"; String rt = args.length > 3 ? args[3].replaceAll("CR", "\r").replaceAll("LF", "\n") : "\n"; BufferedReader r = new BufferedReader(new InputStreamReader(new FileInputStream(args[0]), f)); BufferedWriter w = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(args[0] + "." + t.toLowerCase()), t)); while ((l = r.readLine()) != null) { w.write(l); w.write(rt); } w.close(); r.close(); } }
D:\temp\csv>javac CharConv.java
D:\temp\csv>java CharConv test.csv
(「test.csv」が UTF-8 に変換されて「test.csv.utf8」という名前で出力されます)
オプションとして、第2、3引数で FROM、TO 文字コード、第4引数で改行コードを CRLF で指定できるようにしておきました。なので、java が対応している文字コードであれば、基本的には変換できます。
例えば、上のファイルを UTF-8 から Windows-31J に戻すには、「java CharConv test.csv.utf8 UTF-8 Windows-31J CRLF」のように実行すると、「test.csv.utf8.windows-31j」として変換結果が出力されます。
Windows 以外なら、iconv とか nkf とか使えばいいと思います(Windows で使ってもいいけど)。
journal.json
[
{ "ORDER_NO":1, "PRODUCT_CODE":1, "CUSTOMER_ID":2, "PURCHASE_DATE":"16-01-01" }
, { "ORDER_NO":2, "PRODUCT_CODE":2, "CUSTOMER_ID":2, "PURCHASE_DATE":"16-01-01" }
, { "ORDER_NO":3, "PRODUCT_CODE":1, "CUSTOMER_ID":1, "PURCHASE_DATE":"16-01-02" }
, { "ORDER_NO":4, "PRODUCT_CODE":2, "CUSTOMER_ID":1, "PURCHASE_DATE":"16-01-02" }
, { "ORDER_NO":5, "PRODUCT_CODE":3, "CUSTOMER_ID":1, "PURCHASE_DATE":"16-01-02" }
]
問い合わせ結果
0: jdbc:drill:zk=local> SELECT JSON.ORDER_NO, JSON.PRODUCT_CODE, CSV.PRODUCT_NAME, CSV.PRICE FROM dfs.`D:\temp\csv\journal.json` AS JSON INNER JOIN dfs.`D:\temp\csv\product.csv` AS CSV ON JSON.PRODUCT_CODE = CAST(CSV.PRODUCT_CODE AS INT);
+-----------+---------------+---------------+--------+
| ORDER_NO | PRODUCT_CODE | PRODUCT_NAME | PRICE |
+-----------+---------------+---------------+--------+
| 1 | 1 | 商品1 | 100 |
| 2 | 2 | 商品2 | 200 |
| 3 | 1 | 商品1 | 100 |
| 4 | 2 | 商品2 | 200 |
| 5 | 3 | 商品3 | 150 |
+-----------+---------------+---------------+--------+
5 rows selected (2.742 seconds)
よしよし、イケますね。
ちなみに、Apache Drill が起動した状態で、http://localhost:8047/storage/dfs を開いて、formats の csv に 「"extractHeader": true」を設定してあげると、CSV の先頭行に記述されたカラム名を使えるようになります(詳しい説明は、この辺りをご覧ください)。
※extractHeader を設定していない状態でカラムを指定するには、例えば「alias.columns[0]」のように記述します。
注意点として、CSV のヘッダ行から自動的にカラム名が設定された場合、大文字小文字が区別されるようです。間違って入力してもエラーにならず、空のカラムとして扱われることがあるので分かり難いのですが、そのまま利用すると予想外の結果を招きかねませんので気をつけましょう。
まー、こんな感じで、Apache Drill でも CSV や TSV、JSON などのテキストデータベースを簡単に扱うことはできるのですが、「CSV に SQL でお手軽に問い合わせる」という目的だけを考えると、やはりちょっと立派過ぎると言いますか......ダウンロードするアーカイブのサイズからして 200 MB 近くありますからね。
なんでもできる優秀なコなのに、「あ、そこの CSV ちょろっと編集して、EXCEL に渡しといてー。シクヨロー」みたいな軽い仕事ばっかりさせてたら、「ボ、ボクは......こんなことをする為に、生まれてきたんじゃない!」とかゆって家出されてしまいそうです。
マジで使おうと思ったら、環境構築も結構面倒ですし。
まぁ、中には「え、これ、あり得ないくらい簡単だよね? これが面倒とか、マジそれこそあり得ないと思うんだけど?」みたいな意識高い人もいらっしゃるとは思いますが、分散処理とか別に考えなくていいんで、もーちっとお手軽になんないスカね? みたいなノリで、別の方法も見ていきましょう。
HSQLDB
ということで、お次は HSQLDB(HyperSQL Database Engine)です。
こちらのダウンロードサイズは僅かに 7.8 MB(Ver 2.3.3 時点)と、いきなり圧倒的なダウンサイジングに成功しております(適当な日本語)。
その割りにサーバー機能もついてますし、JDBC ドライバも付属していますし、GUI のマネージャーツールだって付いてきます。至れり尽くせりですね。
ちなみに、HSQLDB は機能の一部として CSV を扱えるというだけで、普通に RDBMS ですので、その辺は誤解のなきよう。
- Apache Drill と同じく、使用言語は Java ですので、なるべく最新の JDK をインストールしておいてください。
- 続いて、本家から最新版をダウンロードして、適当なディレクトリに展開します(2016/01/20 現在で 2.3.3)。
こちらもインストール作業等は必要無く、単純に解凍するだけでおっけーです。 - 「D:\temp\hsqldb-2.3.3\hsqldb」に展開したとして、「bin」ディレクトリ配下には Windows 用のバッチファイルが用意されています。
- が、まぁ、せっかくですから、ここではコードを書いていきましょう。
- 話を HSQLDB に戻して、コマンドを簡潔に記述できるように、まず先に環境変数を設定してしまいましょう。
- HSQLDB は、データソースが CSV であっても CREATE TABLE してテーブルを定義してあげる必要があります。
- さて、それでは SELECT してみましょう。
- でも、CSV ファイル毎に、いちいちテーブルを定義してあげないといけないのは、正直なところ面倒臭いですよね。1行目をヘッダー行として、自動的に設定してくれるといいんですけど。
とはいえ、労力に見合うだけのメリットは、ちゃんと享受できます。
- そして、再び SELECT。
また、必要に応じて環境変数「JAVA_HOME」に JDK をインストールしたフォルダを設定し、「PATH」の先頭に「%JAVA_HOME%\bin」を追加してください。
「runManager.bat」または「runManagerSwing.bat」を実行すると GUI ツールが起動しますので、コマンドラインが苦手な方はそちらを使うと良いかも知れません。
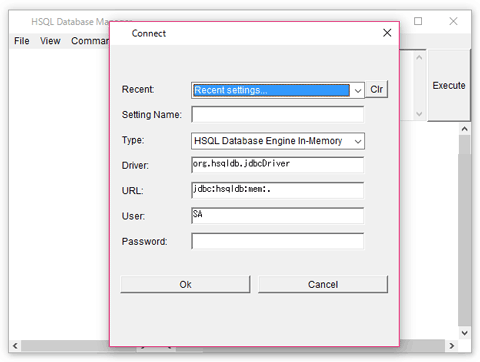
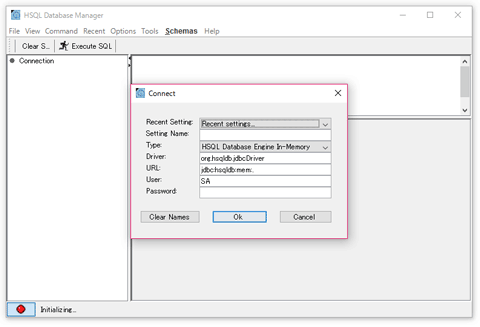
「D:\temp\csv」に「SqlExec.java」という名前でテキストファイルを作成し、以下のコードを入力します。
import java.sql.*;
public class SqlExec {
public static void main(String[] args) throws Exception {
long l1 = System.currentTimeMillis();
String url = null;
String sql = null;
String delimiter = "\t";
String quote = "";
boolean query = false;
boolean verbose = false;
boolean silent = false;
boolean forceHeader = false;
for (int i = 0; i < args.length; i++) {
if (args[i].equalsIgnoreCase("-u")) { url = args[++i]; }
if (args[i].equalsIgnoreCase("-q")) { sql = args[++i]; }
if (args[i].equalsIgnoreCase("-c")) { Class.forName(args[++i]); }
if (args[i].equalsIgnoreCase("-d")) { delimiter = args[++i]; }
if (args[i].equalsIgnoreCase("-t")) { quote = args[++i]; }
if (args[i].equalsIgnoreCase("-r")) { query = true; }
if (args[i].equalsIgnoreCase("-v")) { verbose = true; }
if (args[i].equalsIgnoreCase("-s")) { silent = true; }
if (args[i].equalsIgnoreCase("-h")) { forceHeader = true; }
}
if (url == null || sql == null) { System.out.println("Usage: java SqlExec [-u url] [-q sql] [-c className] [-d delimiter] [-t quote] [-s(silent mode)] [-h(output header line)]"); System.exit(1); }
if (verbose) { System.out.println("DELIMITER [" + delimiter + "]"); System.out.println(" QUOTE [" + quote + "]"); System.out.println(" URL [" + url + "]"); System.out.println(" SQL [" + sql + "]"); System.out.println(); }
Connection conn = DriverManager.getConnection(url);
Statement stmt = conn.createStatement();
long l2 = 0;
int rowCount = 0;
if (sql.trim().toUpperCase().startsWith("SELECT") || query) {
l2 = System.currentTimeMillis();
ResultSet rset = stmt.executeQuery(sql);
ResultSetMetaData rsmd = rset.getMetaData();
if (!silent || forceHeader) {
for (int i = 1; i <= rsmd.getColumnCount(); i++) {
System.out.print((i == 1 ? "" : delimiter).concat(quote).concat(rsmd.getColumnName(i)).concat(quote));
}
System.out.println();
if (!silent) { System.out.println("-------------------------------------------------------------------------------"); }
}
while(rset.next()) {
for (int i = 1; i <= rsmd.getColumnCount(); i++) {
System.out.print((i == 1 ? "" : delimiter).concat(quote).concat(rset.getString(i) == null ? "" : rset.getString(i)).concat(quote));
}
System.out.println();
rowCount++;
}
rset.close();
} else {
l2 = System.currentTimeMillis();
rowCount = stmt.executeUpdate(sql);
}
if (!silent) { System.out.println("takes " + (System.currentTimeMillis() - l2) + " millis (+connect=" + (l2 - l1) + " millis) (" + rowCount + " rows)"); }
stmt.close();
conn.close();
}
}
保存したら、コマンドプロンプトを開いて「D:\temp\csv」に移動し、「javac SqlExec.java」でコンパイルしてください。
このコードは、JDBC さえあれば使い回せるように書いてあります。
具体的な例は、当記事のこれ以降の記述を参照いただくとして、引数の書き方を簡単に説明すると、-u に続けて接続文字列、-q に続けて SQL 文を指定します(今回は必要ありませんが、ユーザーやパスワードを指定する場合は接続文字列に含めてください。なんらかの理由で個別に指定しなければならない場合は、お手数ですが getConnection 辺りを書き換えてください)。
また、基本的には必要ありませんが、オプションとして -c に続けてドライバークラス名を指定できるようにしました。JDBC にクラスパスを確かに通しているのに「No suitable driver found」で SQLException が発生してしまう場合は、指定してみてください。
その他、-d で区切り文字、-t で引用符、-r で executeQuery 強制、-s でサイレントモード(問い合わせ結果のみ出力)、-h でサイレントモード時のヘッダ行出力となっており、例えば JDBC にクラスパスを通した上で「java SqlExec -u "jdbc:hsqldb:file:D:/temp/csv/hsqldb" -q "select * from customer where customer_id < 2" -s -d , -t \^" -h > result.csv」のように実行すれば、問い合わせ結果をヘッダ行付きの CSV としてファイルにリダイレクトできますが、まぁ、この辺りは単なるオマケなので、用途に応じて適当にコードを変更してください。
result.csv(実行結果のサンプル)
"CUSTOMER_ID","FIRST_NAME","LAST_NAME","COUNTRY"
"1","1号","ぐーたら","US"
それから、長くなるので上では触れませんでしたが、このクラスは Apache Drill にも使えます。ただし、Embedded Mode で使う場合は、クラスパスを sqlline と同等に設定し、且つ Windows の場合は conf/drill-override.conf で tmp パス等を適切に設定しておく必要があります(別途サーバーを立ち上げて、それに対して接続を行う場合は JDBC にクラスパスが通ってさえいれば動作します)。
また、Oracle への接続に時間がかかる場合は、こちらの記事を参照してください。
コマンドプロンプトで、以下を実行してください(Linux や Mac では、パスセパレータが ; ではなく : という違いに注意してください)。
Windows の場合
SET CLASSPATH=.;D:\temp\hsqldb-2.3.3\hsqldb\lib\hsqldb.jar;%CLASSPATH%
SET CONN_URL=jdbc:hsqldb:file:D:/temp/csv/hsqldb
クラスパスの設定をご覧いただくと分かるように、要するに hsqldb.jar さえあれば動いちゃうんですね。とても楽で素晴らしい。Apache Drill とは別次元の気軽さです(できることが別次元なので、当たり前なのですが)。
最初に1回だけ、以下を実行してください。
java SqlExec -u %CONN_URL% -q "CREATE TEXT TABLE CUSTOMER (CUSTOMER_ID INTEGER PRIMARY KEY, FIRST_NAME VARCHAR(20), LAST_NAME VARCHAR(20), COUNTRY VARCHAR(2))"
java SqlExec -u %CONN_URL% -q "SET TABLE CUSTOMER SOURCE 'customer.csv;fs=,;encoding=UTF-8;quoted=true;ignore_first=true'"
-q に続く SQL 文をダブルクォーテーションで囲むのを忘れないようにご注意を。
DDL のオプション等について、詳しくはこの辺りを参照してください(CSV を直接操作する場合は、キャッシュさせない方がなにかと分かり易い気がします)。
java SqlExec -u %CONN_URL% -q "SELECT * FROM CUSTOMER"
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM CUSTOMER"
CUSTOMER_ID FIRST_NAME LAST_NAME COUNTRY
-------------------------------------------------------------------------------
1 1号 ぐーたら US
2 2号 ぐーたら JP
上手くいきました。
それは何かといいますと、なんと、CSV に対して直接 INSERT、UPDATE、DELETE が実行できてしまうのです!!
「はぁ? データベースなんだから当たり前だろ」と思いがちですが、INSERT したら、CSV に 1 行追加されるんですよ?
DB 独自のデータファイルではなく、「CSV のまま」各種操作が行えるのは、ここで紹介している他のどの方法でも、HSQLDB ほどお手軽には実現できないのです(と思うのですが、他でも簡単に実現できたら申し訳ないです)。
ということで、試しに INSERT してみましょう。
java SqlExec -u %CONN_URL% -q "INSERT INTO CUSTOMER VALUES(3, '3号', 'ぐーたら', 'JP')"
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM CUSTOMER"
CUSTOMER_ID FIRST_NAME LAST_NAME COUNTRY
-------------------------------------------------------------------------------
1 1号 ぐーたら US
2 2号 ぐーたら JP
3 3号 ぐーたら JP
うん、1行増えてますね。これなら、なんでも出来そう。
ただし、UPDATE や DELETE を行うと、CSV の元の行は削除されるのではなく半角スペースで埋められ、さらに UPDATE の場合は更新結果が新しい行として追加されます(まぁ、そりゃそうですよね)。
なので、HSQLDB だけで CSV を利用している限りは、空白の行を無視してくれるので問題無いのですが、他のシステムと連携する場合は注意が必要です。
H2DB
HSQLDB もいいんだけど、やっぱり CSV なのに、いちいちテーブル定義しないといけないのが面倒臭いんだよねー。
更新とかできなくていいから、参照だけでいいから、もっと簡単に CSV を SELECT できないの?
というワガママボディボイスにお応えしてしまえるのが、これまた軽量のデータベース H2DB です。
HSQLDB 同様、機能の一部として CSV が扱えるという位置づけですが、これはですねー、超お手軽でヤバい簡単です。
早速、導入手順を見ていきましょう。
- 上の2つと同じく、使用言語は Java ですので、なるべく最新の JDK をインストールしておいてください。
- 続いて、本家から最新版をダウンロードして、適当なディレクトリに展開します(2016/01/20 現在で 1.4.190)。
- ダウンロードした zip を「D:\temp\h2」に解凍したとして、「bin」ディレクトリ配下には Windows 用のバッチファイルが用意されています。
- 以降の作業は、もう全部 Web ブラウザ上の管理コンソールでやったらいいじゃない、と思わなくもありませんが、そうもいきませんので、コードを書いていきましょう。
- 続いて、環境変数を設定しましょう。
- そしてぇっ!! 特になんも設定弄ってないのに、たったのこれだけでぇっ!!
- お手軽過ぎて、思わず変なテンションになってしまいましたが、csvread で読み込んだ場合、カラムの型は VARCHAR になるようなので、ご留意ください。これは、納得できる仕様ですよね。
また、必要に応じて環境変数「JAVA_HOME」に JDK をインストールしたフォルダを設定し、「PATH」の先頭に「%JAVA_HOME%\bin」を追加してください。
Windows Installer もダウンロードできますが、ここでは単純な zip ファイルである「All Platforms」の方を選択します。
All Platforms といってもサイズは僅か 8 MB ですし、インストール作業を必要とせず、適当に解凍すれば良いだけの気楽さですし。
「h2.bat」または「h2w.bat」を実行すると、自動的にサーバーが起動し、管理コンソールのログイン画面がシステムデフォルトの Web ブラウザで開かれます。
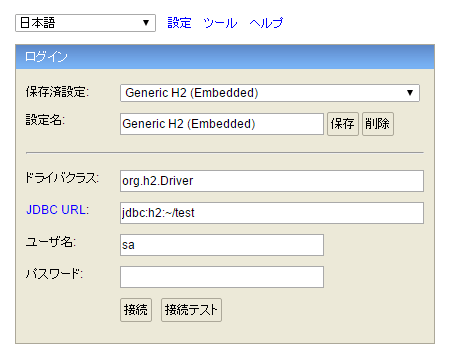
非常にコンパクトでありながら、この利便性は、正直スゴい
と言っても、HSQLDB の 4. をコードを完全にそのまま流用できますので、既に作成してある場合は、特に何もしなくて構いません。
あ、それから、今回はサーバー機能は使いませんので、上で起動したバッチは終了させてしまって構いません。H2DB の設定も、何も弄らなくて結構です。とても、お手軽ですね。
これは、単にコマンドを簡潔に記述できるようにすることが目的なので、別に設定せずに毎回入力しても構いません。
コマンドプロンプトを開いて「D:\temp\csv」に移動し、以下を実行してください(Linux や Mac の場合は、パスセパレータの違いに注意してください)。
Windows
SET CLASSPATH=.;D:\temp\h2\bin\h2-1.4.190.jar;%CLASSPATH%
SET CONN_URL=jdbc:h2:mem:h2test
クラスパスの設定をご覧いただくと分かるように、HSQLDB と同じく、要するに h2-1.4.190.jar だけあれば動いちゃうんですね。至極お手軽で素晴らしいです。逆に、依存関係に雁字搦めに縛られまくったライブラリは好きではありません。
java SqlExec -u %CONN_URL% -q "SELECT * FROM csvread('./product.csv', null, 'charset=UTF-8')"
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM csvread('./product.csv', null, 'charset=UTF-8')"
PRODUCT_CODE PRODUCT_NAME PRICE
-------------------------------------------------------------------------------
1 商品1 100
2 商品2 200
3 商品3 150
うわぁっ!? すげぇ、カラム名が自動的に設定されてるぅっ!!
ここでのキモは、csvread の第2引数です。null を指定すると、CSV の一行目をヘッダー行に見立てて、自動的にカラム名を設定してくれるんですね(詳しくはこの辺りを)。
こ、こんなに楽でいいんですか? いーんです!!
なので、がっつり使う場合はちゃんとテーブルを定義して、そこに取り込んだ方が良いと思います。
でも、ちょっと CSV の一部を SQL で抽出したいだけ、という場合は、SQL の書き方次第で、CSV のままでも大抵はなんとかなります。
わざとらしく、少し複雑に書いてみましょう。
java SqlExec -u %CONN_URL% -q "SELECT CUSTOMER.LAST_NAME || ' ' || CUSTOMER.FIRST_NAME AS CUSTOMER_NAME, PRODUCT.PRODUCT_NAME, JOURNAL.QUANTITY, JOURNAL.PURCHASE_PRICE FROM (SELECT CUSTOMER_ID, PRODUCT_CODE, SUM(1) AS QUANTITY, SUM(CAST(PURCHASE_PRICE AS DOUBLE)) AS PURCHASE_PRICE FROM csvread('./journal.csv', null, 'charset=UTF-8') GROUP BY CUSTOMER_ID, PRODUCT_CODE) AS JOURNAL LEFT JOIN csvread('./product.csv', null, 'charset=UTF-8') AS PRODUCT ON JOURNAL.PRODUCT_CODE = PRODUCT.PRODUCT_CODE LEFT JOIN csvread('./customer.csv', null, 'charset=UTF-8') AS CUSTOMER ON JOURNAL.CUSTOMER_ID = CUSTOMER.CUSTOMER_ID ORDER BY CUSTOMER.CUSTOMER_ID ASC, PRODUCT.PRODUCT_NAME DESC"
CUSTOMER_NAME PRODUCT_NAME QUANTITY PURCHASE_PRICE
-------------------------------------------------------------------------------
ぐーたら 1号 商品3 3 450.0
ぐーたら 1号 商品2 1 200.0
ぐーたら 1号 商品1 1 100.0
ぐーたら 2号 商品2 2 380.0
ぐーたら 2号 商品1 1 95.0
うわぁ、普通に CSV を JOIN できてるぅ~。サブクエリもグルーピングも問題無く使えてるぅ~。すごいぃ~。
最初に試した時の私は、まさしくこんな感じでした(笑)
(でも、パフォーマンスが出ないから、csvread は join で使うなって書いてありますね。それなりのデータを処理する場合は、予め取り込んだ方が良さそうです)
いやぁ、JDBC ってのが、またいいんですよね。
Apach Drill じゃないですけど、JDBC に対応したデータソースなら、プログラムの書き方次第で如何ようにも連携させられますし。
EXCEL のようなアプリケーションを使って GUI 操作で行うには少々複雑な加工をしたいケースでも、自分でちょろっとプログラム書いて、簡単に処理できますし。
それに、後ほど触れますが、妙に高速なんですよ。
個人的には、これでもう十分というか、お腹いっぱいな感じですが、他の方法もまだまだ見ていくことにしましょう。
q - Text as Data
これ以降は、プログラミングというよりも、ツールとしての利用になります。
さて、お次は、近頃「CSV に SQL を投げ隊」界隈で話題沸騰中の期待のコマンドラインツール「q」について取り上げましょう。
各種パッケージマネージャでインストールできますし、Linux や Mac のシェルで標準入出力経由でなんやかんやする場合は、一番お手軽だと思われます。
- 本家から最新版をダウンロードしてください(2016/01/20 時点で 1.5.0)。
- さて、インストーラーやパッケージマネージャでインストールした場合は、既に q が使用可能な状態です。
- それでは、コマンドプロンプトを開いて「D:\temp\csv」に移動し、以下を実行してみましょう。
- うわぁ、お手軽だなぁ。デフォルトで CSV 形式で問い合わせ結果が出力されるので、プログラムから利用することを求めていない場合は、「q」はとても有力な選択肢になると思います。
- また、もちろん JOIN も可能です。
上の3つとは異なり、こちらは Python 製になってますので、Windows ユーザーの多くはアーカイブではなく「windows installer」版を利用した方が楽にインストールできると思います。
そうではなく、アーカイブをダウンロードして自分で解凍した場合は、適当に環境設定をしてください(パスを通して、入ってなければ Python 入れるくらいです)
q "SELECT COUNT(*) FROM ./product.csv"
D:\temp\csv>q "SELECT * FROM ./product.csv"
Warning: column count is one - did you provide the correct delimiter?
PRODUCT_CODE,"PRODUCT_NAME","PRICE"
1,"商品1",100
2,"商品2",200
3,"商品3",150
ところで、上の結果はヘッダー行も含まれちゃってますね。
ヘッダー行からカラム名を自動的に設定するには、-H と -d オプションを指定します。
D:\temp\csv>q -H -d , "SELECT * FROM ./product.csv WHERE PRODUCT_CODE = 2"
D:\temp\csv>D:\temp\csv>q -H -d , "SELECT * FROM ./product.csv WHERE PRODUCT_CODE = 2"
2,商品2,200
オプションについて詳しくは、この辺りを参照してください。
q -H -d , "SELECT JOURNAL.ORDER_NO, JOURNAL.PRODUCT_CODE, PRODUCT.PRODUCT_NAME FROM ./journal.csv AS JOURNAL LEFT JOIN ./product.csv AS PRODUCT ON JOURNAL.PRODUCT_CODE = PRODUCT.PRODUCT_CODE"
D:\temp\csv>q -H -d , "SELECT JOURNAL.ORDER_NO, JOURNAL.PRODUCT_CODE, PRODUCT.PRODUCT_NAME FROM ./journal.csv AS JOURNAL LEFT JOIN ./product.csv AS PRODUCT ON JOURNAL.PRODUCT_CODE = PRODUCT.PRODUCT_CODE"
1,1,商品1
2,2,商品2
3,2,商品2
4,1,商品1
5,2,商品2
6,3,商品3
7,3,商品3
8,3,商品3
うぅん、これはお手軽ですねぇ。
CSV の一部を、ちょこっと SQL で抽出したいだけ、という場合は、これで十分かも知れません。
さらに、将来的には SELECT - INSERT や CREATE TABLE SELECT ~ にも対応する予定みたいです。
でも、FROM 句でサブクエリが使えないんですよね(1.5.0 時点)。
対応自体は予定されているみたいですし、WHERE 句でならサブクエリが使えるとは書いてあるんですが、うーん、なるべく早急に対応して欲しいかなー。
TextQL
「私、ハッカーじゃないので Python なんて知りません!」(偏見)
というあなたには、TextQL はいかがでしょう。
こちら、安心と信頼の Go 言語製となっております。
いや、あの、なんか、探してたら見つかったので、いちおう紹介してみました。
私も試してないですけど。
あっ、すいません、「自分で試してないものを紹介すんな!」というお怒りはご尤もです。
でもですね、あの、README に貼り付けられたアニメ GIF による紹介が、異常に良く出来てましてですね、それを見ただけで、もう試した気分になっちゃったと云いますか。
JOIN もできるみたいですし、q と同じような感覚で使えると思いますので、興味のある方は試してみると良いのではないでしょうか(私は試してないので、自己責任でお願いします)。
と思ったら、紹介されている方がいらっしゃいました。
ご参考まで。
LogParser
さて、続いて Microsoft ご謹製の「LogParser」を紹介しましょう。
Log Parser はログファイル、XML ファイル、CSV ファイルといったテキストデータだけではなく、イベントログ、レジストリ、ファイルシステム、Active Directory® といった Windows® オペレーティングシステム上のデータソースに対し一般的なクエリアクセスを提供する強力で多目的に利用できるツールです。
ということで、特にログファイルを解析する場合に便利だと思います。
Microsoft 謹製ということで、残念ながら対応している環境は Windows だけになります。
- まずは、本家から最新版をダウンロードしてください。
- インストーラーがパスを通してくれたりはしませんので(逆に、わざわざインストーラーを使わなくても、フォルダごとコピペするだけで別のマシンでも使えます)、コマンドプロンプトを開いて以下を実行してください(常用する場合は、コントロールパネルの「システム」から、環境変数で Path を設定すると良いでしょう)。
- 以上で、準備は完了です。
- ここまで見てきた限りでは、割りとお手軽で良さそうですが、残念ながら JOIN ができません。
SET PATH=C:\Program Files (x86)\Log Parser 2.2;%PATH%
念の為に注釈しておきますが、32 bit 版の Windows では「Program Files (x86)」は「Program Files」になる筈です。実際のフォルダ名を確認して設定してください。
「D:\temp\csv」に移動して、早速 SQL を投げてみましょう。
logparser -i:CSV "SELECT * FROM product.csv"
D:\temp\csv>logparser -i:CSV "SELECT * FROM product.csv"
エラー: ログのロウが長すぎます。
ログファイル "D:\temp\csv\product.csv", ロウ番号 3
ああ、うん......文字コードは Windows-31J(≒Shift_JIS)、改行コードは CRLF(\r\n)じゃないとダメなんですね。
まぁ、結構昔に作られたツールだからなぁ(最終更新は 2008 年)。Windows Only 前提のツールだからか、文字コードや改行コードに関するオプションも見当たりません。
「CHCP 65001」としても、改行コードで引っ掛かって上手く動かないので、仕方なく文字コードを Windows-31J、改行コードを CRLF に変換して product.csv.windows-31j として保存します。
で、そちらに対して実行すると、こんな感じで上手くいきます。
logparser -i:CSV "SELECT * FROM product.csv.windows-31j"
logparser -i:CSV "SELECT * FROM product.csv.windows-31j"
Filename RowNumber PRODUCT_CODE PRODUCT_NAME PRICE
---------------------------- --------- ------------ ------------ -----
D:\temp\csv\product_sjis.csv 2 1 商品1 100
D:\temp\csv\product_sjis.csv 3 2 商品2 200
D:\temp\csv\product_sjis.csv 4 3 商品3 150
統計情報:
---------
処理された要素: 3
出力された要素: 3
実行時間: 0.01 秒
product.csv.windows-31j を product2.csv.windows-31j にコピーして、2行めを削除したとして、こんな感じにサブクエリーは使えるんですけどね。
logparser -i:CSV "SELECT * FROM product.csv.windows-31j WHERE PRODUCT_CODE IN (SELECT PRODUCT_CODE FROM product2.csv.windows-31j)"
D:\temp\csv>logparser -i:CSV "SELECT * FROM product.csv.windows-31j WHERE PRODUCT_CODE IN (SELECT PRODUCT_CODE FROM product2.csv.windows-31j)"
Filename RowNumber PRODUCT_CODE PRODUCT_NAME PRICE
---------------------------- --------- ------------ ------------ -----
D:\temp\csv\product_sjis.csv 2 1 商品1 100
D:\temp\csv\product_sjis.csv 4 3 商品3 150
統計情報:
---------
処理された要素: 3
出力された要素: 2
実行時間: 0.01 秒
また、「logparser -i:CSV "SELECT * FROM *.csv"」のように、データソースを一括して指定することもできるのですが、この場合は、例えば同一フォルダに存在する日付毎のアクセスログファイルのように、CSV の中身のフォーマットが一致している必要があります(というより、一致していないと意味がありません)。
ファイルを + で連結する感じですかね。SQL で言えば、イメージ的には UNION ALL でしょうか。
その名の通り、決まったフォーマットのログファイルを扱うには、とても便利だと思いますが(CSV だけでなく、色々な種類のログファイルを扱えますしね)、ここまで見てきた他の方法に比べると、汎用性はちょっと落ちちゃいますかねー。
あと、Microsoft と言えば、VBS 等で ADO を利用する方法も紹介しようかと思ったのですが、こちらも単純には JOIN できませんし、書き方も割りと環境に依存してしまうので、今回は見送りました。
気になる方は、以下の記事などを参考にしてください。
GUI ツール
さて、ここまではコンソール上で使うものばかりでしたが、GUI アプリケーションも少しだけ紹介しておきます。
実際は、SQLite のフロントエンドのようです。
CSV のインポートができるので、その後は当然 SQL で扱えるということですね。
ということは、加工した結果を CSV に戻すにはエクスポートが必要であり、当記事の趣旨と少し外れるような気もしますが、とにかく GUI で操作したいという方は試してみても良いのではないでしょうか。
他にも紹介しようかと思ったのですが、インポート・エクスポートまでアリにしてしまうと、よく考えたら各種 DB の管理ツールなら大体できてしまうような気がするので、今回個別に取り上げるのはこれだけにしておきます。
パフォーマンス対決
さてさて、お待ちかねのパフォーマンス対決のお時間です。
え? 待ってたのは、お前だけだろって?
いやだなぁ、こんな記事、それほど多くの人が読む訳ありませんもの。そんなこと、言われなくったって重々承知してますよ!(血涙)
で、これまで紹介してきた方法を使うと、それぞれどのくらいの速さで CSV を検索したりできるのか、軽く調べて結果を並べてみようかと思ったのですが、その為には、まずサンプルデータが無いとはじまりません。
例によって郵便番号データでも使おうかと思ったのですが、せいぜい十数万件のデータでは少々物足りないというものです。
できれば 100 万行くらいは欲しいところですが、探すのが面倒だったので、以下のコードを使ってこちらで出力しました。
まぁ、そんなに複雑な調査をするつもりは無いので、別にいいですよね!(良くない)
SampleData.java
import java.io.*;
import java.util.*;
import java.text.*;
public class SampleData {
public static void main(String[] args) throws Exception {
final String AVAILABLE_CHARS = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ-=+?/#$()_[]@:;~{}!*.";
int lineCount = Integer.parseInt(args[0]);
int columnSet = args.length > 1 ? Integer.parseInt(args[1]) : 10;
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
Calendar cal = Calendar.getInstance();
Random rand = new Random();
StringBuilder sb = new StringBuilder();
BufferedWriter writer = new BufferedWriter(new FileWriter("sampledata.csv"));
sb.append("\"PKEY\",\"PGRP\"");
for (int i = 0; i < columnSet; i++) {
sb.append(",\"VCHAR").append(i).append("\",\"INTEGER").append(i).append("\",\"TIMESTAMP").append(i).append("\"");
}
sb.append("\n");
writer.write(sb.toString());
for (int i = 1; i <= lineCount; i++) {
sb.setLength(0);
sb.append(i).append(",").append((i - 1) / ((10 * Math.round(Math.log10(lineCount))) + 1));
for (int j = 0; j < columnSet; j++) {
int length = rand.nextInt(15) + 5;
sb.append(",\"");
for (int k = 0; k < length; k++) {
sb.append(AVAILABLE_CHARS.charAt(rand.nextInt(AVAILABLE_CHARS.length())));
}
cal.add(Calendar.MILLISECOND, rand.nextInt(864000000) - 432000000);
sb.append("\",").append(rand.nextInt(rand.nextInt(Integer.MAX_VALUE))).append(",\"").append(sdf.format(cal.getTime())).append("\"");
}
sb.append("\n");
writer.write(sb.toString());
}
writer.close();
}
}
コンパイルして、以下のように実行すると、中身が極めて適当な 100 万行のデータが sampledata.csv に出力されます。
java SampleData 1000000
色々とツッコみたいこともおありでしょうが、そういうのは一切無視しまして、まずは単純にプライマリキー的な一意のキー項目を指定して抽出するところから初めてみましょう。
※特に何も定義していない素の CSV なので、それっぽいというだけで、実際はプライマリキーではありません(HSQLDB でもプライマリキーとして設定していません)。
- PKEY = 999999
- TIMESTAMP1 = CURRENT_DATE(年月日の一致)
- 数値の範囲指定とグルーピング
Apache Drill
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM dfs.`D:\temp\csv\sampledata.csv` WHERE PKEY = 999999" -c org.apache.drill.jdbc.Driver
PKEY PGRP VCHAR0 INTEGER0 TIMESTAMP0 VCHAR1 INTEGER1 TIMESTAMP1 VCHAR2 INTEGER2 TIMESTAMP2 VCHAR3 INTEGER3 TIMESTAMP3 VCHAR4 INTEGER4 TIMESTAMP4 VCHAR5 INTEGER5 TIMESTAMP5 VCHAR6 INTEGER6 TIMESTAMP6 VCHAR7 INTEGER7 TIMESTAMP7 VCHAR8 INTEGER8 TIMESTAMP8 VCHAR9 INTEGER9 TIMESTAMP9
-------------------------------------------------------------------------------
999999 16393 c=O9ncA 825201096 1972-06-11 08:47:07.674 MPhb$j! 42242199 1972-06-08 21:05:07.490 }hR/2UZL 275124347 1972-06-04 01:30:05.627 i2dN[@7AQ=MA~N2b! 268923575 1972-05-31 16:44:05.981 bVhFx-y99ge3gpy(T4+ 36360027 1972-05-31 14:43:32.510 $Eqfxgdo 479931939 1972-06-01 23:27:57.244 BV?DY7iQ8mVz03( 111921284 1972-05-30 13:31:31.210 EBqHmgqW;_]e 730945559 1972-06-02 11:29:16.283 y4U#08B 79234647 1972-05-28 17:32:44.636 bAIYFfuranOFGCW;R 667095746 1972-05-27 02:31:01.862
takes 8483 millis (+connect=1356 millis) (1 rows)
※パッと見文字化けして見えますが、sampledata.csv の文字列項目がランダムなだけです
HSQLDB
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM SAMPLE_DATA WHERE PKEY = 999999"
PKEY PGRP VARCHAR0 INTEGER0 TIMESTAMP0 VARCHAR1 INTEGER1 TIMESTAMP1 VARCHAR2 INTEGER2 TIMESTAMP2 VARCHAR3 INTEGER3 TIMESTAMP3 VARCHAR4 INTEGER4 TIMESTAMP4 VARCHAR5 INTEGER5 TIMESTAMP5 VARCHAR6 INTEGER6 TIMESTAMP6 VARCHAR7 INTEGER7 TIMESTAMP7 VARCHAR8 INTEGER8 TIMESTAMP8 VARCHAR9 INTEGER9 TIMESTAMP9
-------------------------------------------------------------------------------
999999 16393 c=O9ncA 825201096 1972-06-11 08:47:07.674000 MPhb$j! 42242199 1972-06-08 21:05:07.490000 }hR/2UZL 275124347 1972-06-04 01:30:05.627000 i2dN[@7AQ=MA~N2b! 268923575 1972-05-31 16:44:05.981000 bVhFx-y99ge3gpy(T4+ 36360027 1972-05-31 14:43:32.510000 $Eqfxgdo 479931939 1972-06-01 23:27:57.244000 BV?DY7iQ8mVz03( 111921284 1972-05-30 13:31:31.210000 EBqHmgqW;_]e 730945559 1972-06-02 11:29:16.283000 y4U#08B 79234647 1972-05-28 17:32:44.636000 bAIYFfuranOFGCW;R 667095746 1972-05-27 02:31:01.862000
takes 29551 millis (+connect=227 millis) (1 rows)
H2DB
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM csvread('./sampledata.csv', null, 'charset=UTF-8') WHERE PKEY = 999999"
PKEY PGRP VCHAR0 INTEGER0 TIMESTAMP0 VCHAR1 INTEGER1 TIMESTAMP1 VCHAR2 INTEGER2 TIMESTAMP2 VCHAR3 INTEGER3 TIMESTAMP3 VCHAR4 INTEGER4 TIMESTAMP4 VCHAR5 INTEGER5 TIMESTAMP5 VCHAR6 INTEGER6 TIMESTAMP6 VCHAR7 INTEGER7 TIMESTAMP7 VCHAR8 INTEGER8 TIMESTAMP8 VCHAR9 INTEGER9 TIMESTAMP9
-------------------------------------------------------------------------------
999999 16393 c=O9ncA 825201096 1972-06-11 08:47:07.674 MPhb$j! 42242199 1972-06-08 21:05:07.490 }hR/2UZL 275124347 1972-06-04 01:30:05.627 i2dN[@7AQ=MA~N2b! 268923575 1972-05-31 16:44:05.981 bVhFx-y99ge3gpy(T4+ 36360027 1972-05-31 14:43:32.510 $Eqfxgdo 479931939 1972-06-01 23:27:57.244 BV?DY7iQ8mVz03( 111921284 1972-05-30 13:31:31.210 EBqHmgqW;_]e 730945559 1972-06-02 11:29:16.283 y4U#08B 79234647 1972-05-28 17:32:44.636 bAIYFfuranOFGCW;R 667095746 1972-05-27 02:31:01.862
takes 7186 millis (+connect=211 millis) (1 rows)
q
D:\temp\csv>q -H -d , "SELECT * FROM ./sampledata.csv WHERE PKEY = 999999"
999999,16393,c=O9ncA,825201096,1972-06-11 08:47:07.674,MPhb$j!,42242199,1972-06-08 21:05:07.490,}hR/2UZL,275124347,1972-06-04 01:30:05.627,i2dN[@7AQ=MA~N2b!,268923575,1972-05-31 16:44:05.981,bVhFx-y99ge3gpy(T4+,36360027,1972-05-31 14:43:32.510,$Eqfxgdo,479931939,1972-06-01 23:27:57.244,BV?DY7iQ8mVz03(,111921284,1972-05-30 13:31:31.210,EBqHmgqW;_]e,730945559,1972-06-02 11:29:16.283,y4U#08B,79234647,1972-05-28 17:32:44.636,bAIYFfuranOFGCW;R,667095746,1972-05-27 02:31:01.862
takes 93174 millis. (1 rows)
LogParser
D:\temp\csv>logparser -i:CSV "SELECT * FROM sampledata.csv WHERE PKEY = 999999"
Filename RowNumber PKEY PGRP VCHAR0 INTEGER0 TIMESTAMP0 VCHAR1 INTEGER1 TIMESTAMP1 VCHAR2 INTEGER2 TIMESTAMP2 VCHAR3 INTEGER3 TIMESTAMP3 VCHAR4 INTEGER4 TIMESTAMP4 VCHAR5 INTEGER5 TIMESTAMP5 VCHAR6 INTEGER6 TIMESTAMP6 VCHAR7 INTEGER7 TIMESTAMP7 VCHAR8 INTEGER8 TIMESTAMP8 VCHAR9 INTEGER9 TIMESTAMP9
-------------------------- --------- ------ ----- ------- --------- ------------------- ------- -------- ------------------- -------- --------- ------------------- ----------------- --------- ------------------- ------------------- -------- ------------------- -------- --------- ------------------- --------------- --------- ------------------- ------------ --------- ------------------- ------- -------- ------------------- ----------------- --------- -------------------
d:\temp\csv\sampledata.csv 1000000 999999 16393 c=O9ncA 825201096 1972-06-11 08:47:07 MPhb$j! 42242199 1972-06-08 21:05:07 }hR/2UZL 275124347 1972-06-04 01:30:05 i2dN[@7AQ=MA~N2b! 268923575 1972-05-31 16:44:05 bVhFx-y99ge3gpy(T4+ 36360027 1972-05-31 14:43:32 $Eqfxgdo 479931939 1972-06-01 23:27:57 BV?DY7iQ8mVz03( 111921284 1972-05-30 13:31:31 EBqHmgqW;_]e 730945559 1972-06-02 11:29:16 y4U#08B 79234647 1972-05-28 17:32:44 bAIYFfuranOFGCW;R 667095746 1972-05-27 02:31:01
統計情報:
---------
処理された要素: 1000000
出力された要素: 1
実行時間: 34.10 秒
SqlExec では SQL 発行~問い合わせ結果を全て取得できたところまでの時間を計測しています。
また、Apache Drill と HSQLDB は、上で見てきたような SQL を投げる度にいちいちサーバーを起ち上げて接続するやり方だと、SQL のパフォーマンスとは直接関係の無い部分で非常に時間がかかってしまう為、localhost にサーバーを立てて、そこに接続しています。
ただ、それだとプロセスの起動~完了まで全て含めて計測するしかない、ツールである q や LogParser が不利になってしまうので、参考として起動~接続完了までのミリ秒も出力しました(+connect ... millis というのがソレです)。
とはいえ、それを考慮しても、q が意外なほど遅い――と思ったら、これ、要するに SQLite なんですね。ならまぁ、こんなもんかなぁ。Windows 環境ですし、参考程度に。
それに引き換え、H2DB が異常に速いです。最初は、メモリ上にテーブル作ってるのかなー、でっかいデータだと OutOfMemoryError が発生しちゃうんじゃないかなー、などと心配していたのですが、とんでもない。なに、この速度。
蓋を開けてみたら、Apache Drill より速いじゃないですかー、やだー。
しかも、わざわざサーバーを立てる必要すら無いんですよ。
......え? いくらなんでもスゴ過ぎない?
※ここから、問い合わせ結果は省略して処理時間のみ掲載します
Apache Drill
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM dfs.`D:\temp\csv\sampledata.csv` WHERE TO_CHAR(TO_TIMESTAMP(TIMESTAMP1, 'yyyy-MM-dd HH:mm:ss.SSS'), 'yyyyMMdd') = TO_CHAR(CURRENT_DATE, 'yyyyMMdd')" -c org.apache.drill.jdbc.Driver
takes 10608 millis (+connect=2065 millis) (25 rows)
HSQLDB
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM SAMPLE_DATA WHERE TO_CHAR(TIMESTAMP1, 'YYYYMMDD') = TO_CHAR(CURRENT_DATE, 'YYYYMMDD')"
takes 34332 millis (+connect=223 millis) (25 rows)
H2DB
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT * FROM csvread('./sampledata.csv', null, 'charset=UTF-8') WHERE FORMATDATETIME(PARSEDATETIME(TIMESTAMP1, 'yyyy-MM-dd HH:mm:ss.SSS'), 'yyyyMMdd') = FORMATDATETIME(CURRENT_DATE, 'yyyyMMdd')"
takes 16299 millis (+connect=177 millis) (25 rows)
q
q -H -d , "select * from ./sampledata.csv where strftime('%Y%m%d', timestamp1) = strftime('%Y%m%d', datetime('now', 'localtime'))"
takes 95702 millis. (25 rows)
LogParser
logparser -i:CSV -o:CSV "SELECT * FROM sampledata.csv WHERE TO_STRING(TIMESTAMP1, 'yyyyMMdd') = TO_STRING(TO_LOCALTIME(SYSTEM_TIMESTAMP()), 'yyyyMMdd')"
統計情報:
---------
処理された要素: 1000000
出力された要素: 25
実行時間: 33.73 秒
今回は、辛うじて Apache Drill の方が速いですが、ジツは H2DB は PARSEDATETIME を省いて暗黙の型変換を用いても同じ結果を得ることができまして(Drill はダメ)、そちらだと約 13000 ミリ秒まで処理時間は短縮され、差がほとんど無くなります。
ていうか、このくらい単純な条件だと、全員1つ目とほぼ変わらないですね。
Apache Drill
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT PGRP, SUM(CAST(INTEGER9 as INT)) AS SUM9, COUNT(*) AS CNT FROM dfs.`D:\temp\csv\sampledata.csv` WHERE CAST(INTEGER9 as INT) > 10000 AND CAST(INTEGER9 as INT) < 100000 GROUP BY PGRP ORDER BY CAST(PGRP as INT)" -c org.apache.drill.jdbc.Driver
takes 7881 millis (+connect=1330 millis) (464 rows)
HSQLDB
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT PGRP, SUM(INTEGER9) AS SUM9, COUNT(*) AS CNT FROM SAMPLE_DATA WHERE INTEGER9 > 10000 AND INTEGER9 < 100000 GROUP BY PGRP ORDER BY PGRP"
takes 29800 millis (+connect=251 millis) (464 rows)
H2DB
D:\temp\csv>java SqlExec -u %CONN_URL% -q "SELECT PGRP, SUM(CAST(INTEGER9 as INT)) AS SUM9, COUNT(*) AS CNT FROM csvread('./sampledata.csv', null, 'charset=UTF-8') WHERE CAST(INTEGER9 as INT) > 10000 AND CAST(INTEGER9 as INT) < 100000 GROUP BY PGRP ORDER BY CAST(PGRP as INT)"
takes 7092 millis (+connect=177 millis) (464 rows)
q
q -H -d , "SELECT PGRP, SUM(INTEGER9) AS SUM9, COUNT(*) AS CNT FROM ./sampledata.csv WHERE INTEGER9 > 10000 AND INTEGER9 < 100000 GROUP BY PGRP ORDER BY PGRP"
takes 93134 millis. (464 rows)
LogParser
logparser -i:CSV -o:CSV "SELECT PGRP, SUM(INTEGER9) AS SUM9, COUNT(*) AS CNT FROM sampledata.csv WHERE INTEGER9 > 10000 AND INTEGER9 < 100000 GROUP BY PGRP ORDER BY PGRP"
統計情報:
---------
処理された要素: 1000000
出力された要素: 464
実行時間: 32.97 秒
あれー、このくらいじゃ、処理時間ぜんぜん変わんないかー。3つに分けた意味無かったッスね、これ(いちおう、文字列項目に対して LIKE 検索も試してみましたが、結果はほぼ同じでした)。
ま、まぁ、この程度の条件なら、どれもパフォーマンスが落ちないことは確認できたしィ? てか、それを確認したかったんだしィ?(震え声)
いえ、あの、本当はもう少し複雑なクエリで計測したかったんですけど、q には FROM 句でサブクエリが使えない縛りが、LogParser には JOIN できない縛りがありましてですね。
さらに、それぞれ通る SQL にかなりクセがあったりして、全部でエラーが出ないように書こうとすると、どうしても単純な文になってしまいがちなのと、調子の乗ってサブクエリとかを書きはじめると、途端に返ってこないほど重くなってしまうコとかもいまして、これ以上アレコレ試してる時間もちょっと無かったので、このような不甲斐無い結果となってしまいました。
本当にすみませんです。
とりあえず、これで勘弁してください。なんでもはしませんけど。
まとめ
ていうか、built-in function の書き方が、いちいち違ってて面倒臭いんじゃーっ!!
HSQLDB は、定義したテーブルのデータ量に比例して起動がやたらと重くなるので、大きなデータを扱う場合はサーバーを立てないと厳しいと思います。そうなると、ちょっとした加工に気軽に利用する、という使い方は難しくなっちゃいますね。でも、その代わりに JOIN 等で極端に重くならないという利点もあります(上で触れたように、CSV の更新も行えますし)。
H2DB は基本的に恐ろしく優秀なのですが、そこそこデータ量のある CSV を扱う場合は、SQL の書き方次第で非常に重くなってしまうことがあるようです(WHERE 句のサブクエリや JOIN で別の CSV を指定したりとか)。でも、まぁ、どんな DBMS でも得手不得手はありますし、SQL の書き方を工夫するだけですが、どうしても書き方では回避できない場合は、必要なデータを予めテーブルに取り込んでおくと良いでしょう。
その点で言えば、さすがに Apache Drill は SQL が複雑でも比較的パフォーマンスが落ちにくい印象でした。でも、起動にいちいち時間がかかるし、環境構築も面倒臭いので、やっぱりこの面子の中ではお手軽ではないです。
q は、処理対象のデータが大きいと、クエリを実行するより前の段階で、SQLite との内部的な連携に時間がかかってしまうように思えます。毎回コマンドとして実行する前提の作りでこれだと、巨大なデータには向かないかも。
LogParser も、実行時間が毎回ほぼ同じことから察するに、要は全行を舐める為に必要な時間ですよね、これ。よほど複雑なクエリを組まない限り、処理時間はモロにデータサイズに比例しそうです。いかにもログ解析ツールっぽい動きですが、このくらいの速度で動いてくれれば、ログ用としては十分でしょうか。
おわりに
つ、疲れた......
でも、その甲斐あって、用途によってどれを選べば良いのか、なんとなく分かってきましたね。
とにかく簡単に CSV に対して SQL で問い合わせを行いたいのであれば、手軽さとパフォーマンスのバランスがズバ抜けている H2DB。
リダイレクトによる出力等ではなく、対象の CSV を直接更新する必要がある場合は H2DB。
複雑なクエリを発行したり、分散化が必要だったり、多様で大規模なデータソースを組み合わせたい場合は Apache Drill。
プログラム無しで、コマンドラインだけで完結させたいなら q。
Windows 上でのログの解析なら LogParser といったところでしょうか。
本当は、もうちょっとまともな調査になる予定だったのですが、自分がやろうとしたような作業には、H2DB がファーストチョイスだなーと分かったので、まー個人的には良しとします(笑)
他の方にも、少しはお役に立っているとよいのですが。
それから、いつものことなのですが、記事を投稿してしばらくは内容が頻繁に更新されますので、キャッシュが強い環境では必要に応じてリロードしていただけるとありがたいです。
 macOS High Sierra にアップグレードしたら、CocoaPods が動かなくなった
macOS High Sierra にアップグレードしたら、CocoaPods が動かなくなった Swift 4 で substring 的にインデックスを指定して部分文字列を取り出す方法
Swift 4 で substring 的にインデックスを指定して部分文字列を取り出す方法 外部 CSS ファイルにインラインで SVG を埋め込む方法
外部 CSS ファイルにインラインで SVG を埋め込む方法 Excelで数の決まっていないリストからランダムに項目を選択する方法
Excelで数の決まっていないリストからランダムに項目を選択する方法 [WPF] 複数のトリガー条件を組み合わせた時に AND だけでなく OR で判断する方法
[WPF] 複数のトリガー条件を組み合わせた時に AND だけでなく OR で判断する方法 数ヶ月越しで我が家にお越しいただいた Alexa と戯れる(Amazon Echo Dot の感想)
数ヶ月越しで我が家にお越しいただいた Alexa と戯れる(Amazon Echo Dot の感想) コルタナさん、もう少し静かに喋っていただけますか(アプリ毎にボリュームを設定する方法)
コルタナさん、もう少し静かに喋っていただけますか(アプリ毎にボリュームを設定する方法) iPhone X で手軽にホーム画面の1枚目に戻ったりアプリの削除画面を完了する方法
iPhone X で手軽にホーム画面の1枚目に戻ったりアプリの削除画面を完了する方法 iPhone X の Face ID が全然認識しないと思ったら、まるきり自分のせいだった話
iPhone X の Face ID が全然認識しないと思ったら、まるきり自分のせいだった話 iOS 11以降は、Apple IDの2ステップ確認には対応せず、2ファクタ認証に一本化される模様
iOS 11以降は、Apple IDの2ステップ確認には対応せず、2ファクタ認証に一本化される模様